“树状数组和线段树都是用于维护数列信息的数据结构,支持单点/区间修改,单点/区间询问信息。以增加权值与询问区间权值和为例,其余的信息需要维护也都类似。时间复杂度均为O(logn)。 ”
I. 树状数组
Fenwick Tree
地中海的程序猿们研究数组,时候遇到这样一个问题: 有一个数组从,现在要在 的时间复杂度内,搜索一个确定的值(或修改)并且对区间 求和。空间复杂度必须严格限制在.
他们想到了二叉搜索树(BST),对于平衡二叉树其插入和删除的时间复杂度都是,因为树是类似于嵌套列表的思想,进而可以想到二叉堆,这是一种非嵌套列表,也可以实现。于是有了下面这张图:
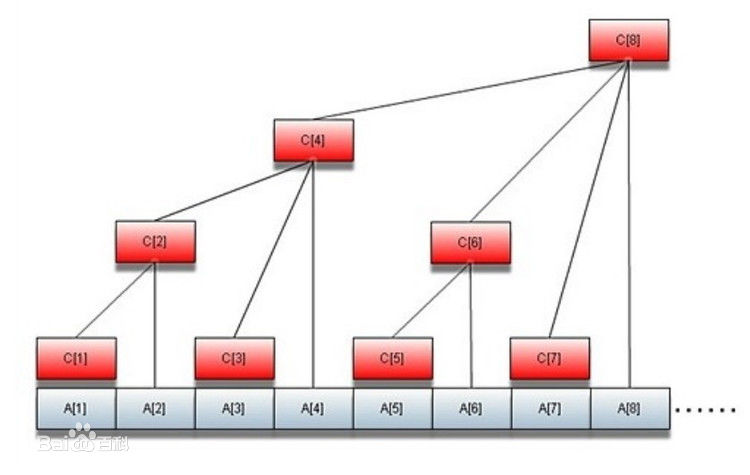
解释一下,编号为的节点上统计着这一段区间的信息,的父亲就是,我们要维护数组上的信息,存储在数组中。
按照Peter M. Fenwick的说法,正如所有的整数都可以表示成2的幂和,我们也可以把一串序列表示成一系列子序列的和。采用这个想法,我们可将一个前缀和划分成多个子序列的和,而划分的方法与数的2的幂和具有极其相似的方式。一方面,子序列的个数是其二进制表示中1的个数,另一方面,子序列代表的的个数也是2的幂。
1. Lowbit函数
返回参数转换为二进制后,最后一个1的位置所代表的数值。
比如34转换为二进制就是0010 0010, Lowbit(34)返回2. 程序上 我们可以用((Not I)+1) AND I, 比如NOT(0010 0010) = 1101 1101, 加1之后为 1101 1110,再与上I,为0000 0010(2)。
int lowbit(int x)
{
return x&(-x);
}
2. 新建数组
我们定义一个数组BIT,用以维护A的前缀和,
void build()
{
for (int i = 1; i <= MAX_N; i++)
{
BIT[i] = A[i - 1];
for (int j = i - 2; j >= i - lowbit(i); j--)
BIT[i] += A[j];
}
}
3. 修改
假设现在要在的值增加, 那么需要将在所有含的区间都加上一个数,
void add(int k, int w)
{// 在下标k、加上w
for(int j = k; j< tr.size();j+=low_bit(j)) tr[j]+=w;
}
4. 区间求和
假设我们需要计算的值。
- 首先,将初始化为
- 将的值加上
- 将的值减去
- 重复2 . 3 步骤直到的值变为0.
int sum (int k)
{
int ans = 0;
for (int i = k; i > 0; i -= lowbit(i))
ans += BIT[i];
return ans;
}
应用:求逆序数
II. 线段树
Segment Tree
使用线段树可以快速查找某一个节点在若干线段中出现的次数,时间复杂度为,而未优化的空间复杂度为,一般要开的数组防止越界。

除了叶子节点外,对于线段节点,其有两个子节点, 左子节点和右子节点。由于线段树在程序竞赛中被广泛应用,这种结构被和戏谑为必须掌握的数据结构。一般地,我们先定义一个线段树节点结构体:
struct SegmentNode
{
int start;//线段左节点
int end;//线段右节点
int sum;//线段对应的和
int lazytag;//懒标记
SegmentNode *left;
SegmentNode *right;
SegmentNode():start(0),end(0),sum(0){}
};
请务必熟悉理解上述结构!
1. 建立树
我们对区间建立线段树,是一个自上而下过程。
inline void build(SegmentNode *self, int l, int r)
{
if(l>r) return;
self->start = l;self->end = r;
if(l==r)
{
return;
}
int mid = (l+r)>>1;
self->left = new SegmentNode();
build(self->left,l,mid);
self->right = new SegmentNode();
build(self->right,mid+1,r);
}
2. 单点修改
从根节点开始,以递归的方式不断更新sum值,直到叶子节点即区间长度为1,每个区间的sum值等于左子区间的sum值,加上右子区间的sum值。
inline void add(SegmentNode *self, int pos, int k)
{
if(pos<self->start||pos>self->end) return;
if(self->start == self->end)
{
self->sum += k;
return;
}
if(self->right->start>pos) add(self->left,pos,k);
else add(self->right,pos,k);
self->sum = self->left->sum + self->right->sum;
}
3. 区间查询
- 第一种情况是当前的区间范围完全在内,这个时候把当前区间的值返回即可,
- 第二张情况是当前节点的
左子节点的右端点和有交集。这个时候就搜索左子节点。 - 第三张情况是当前节点的
右子节点的左端点和有交集。这个时候就搜索右子节点。inline int search(SegmentNode *self, int i,int j) {//这里的i,j分别代表要搜索的区间 if(i>j) return 0; if(i<=self->start && self->end<=j) { return self->sum; } int s = 0; if(self->left->end>=i) s+=search(self->left,i,j); if(self->right->start<=j) s+=search(self->right,i,j); return s; }4. 延迟标记
对于区间修改,这里会遇到一个问题:为了使所有sum值都保持正确,每一次插入操作可能要更新个sum值,从而使时间复杂度退化为。所以就有了Lazytag,如果一个节点有延迟标记,那么表明这个节点已经被修改过了。
void add_tag(SegmentNode *self,int l,int r,int v) {
self->sum += (r-l+1)*v;self->lazytag+=v;//标记只对儿子有影响,自己在打标记的同时一起把统计信息更改了。
}
void push_down(SegmentNode *self,int l,int r) {
int mid=(l+r)>>1;
add_tag(self->left,l,mid,self->lazytag);
add_tag(self->right,mid+1,r,self->lazytag);
self->lazytag = 0;//把当前标记分别传给两个儿子然后清空
}
inline int search(SegmentNode *self, int l, int r,int v) {//[l,r]为当前区间,[L,R]为要修改的区间
if(l<=self->start && self->end<=r) {
add_tag(self,l,r,v);//打标记
return;
}
int s = 0;
push_down(self,l,r);//下传标记
if(self->left->end>=i) s+=search(self->left,i,j,v);
if(self->right->start<=j) s+=search(self->right,i,j,v);
return s;
}
III. 树状数组和线段树比较
|数据结构|时间复杂度|空间复杂度|适用特点| |:—:|:—:|:—:|:—:| |线段树||O(N)|-| |树状数组||O(N)|空间复杂度略低,容易扩展到多维,适用范围较线段树小| |
下面看一些经典题目吧
53. 最大子序和
其实这题除了用动态规划,还可以用线段树做。
这个分治方法类似于「线段树求解 LCIS 问题」的 pushUp 操作。 当然,如果读者有兴趣的话,推荐看一看线段树区间合并法解决 多次询问 的「区间最长连续上升序列问题」和「区间最大子段和问题」,还是非常有趣的。
我们定义一个操作get(a,l,r)表示查询a序列间内的最大字段和。对于一个区间,我们取,然后逐层递归。最关键的问题是:
-
我们要维护区间什么信息?
-
我们如何合并这些信息?
对于一个区间,
lSum表示以为左端点的最大子段和;rSum表示以为右端点的最大子段和,mSum表示内的最大子段和。
iSum表示的区间和。iSum是左右区间的子段和的和。- 对于 的
lSum,存在两种可能,它要么等于「左子区间」的lSum,要么等于「左子区间」的iSum加上「右子区间」的lSum,二者取大。 - 对于 的
rSum,存在两种可能,它要么等于「右子区间」的rSum,要么等于「右子区间」的iSum加上「左子区间」的rSum,二者取大。 - 对于
mSum,存在三种可能,要么完全在左区间,要么完全在中间,要么两边都有,我想你已经猜到了,就是左区间的rSum加上右区间的lSum。
好的已经可以开始写代码了
struct Status
{
int lSum, rSum, mSum, iSum;
// 分别表示,以l为左端点的最大子序和,以r为右端点的最大子序和,
// mSum表示区间[l,r]最大子序和
//iSum表示区间和
};
Status get(vector<int> nums,int l,int r)
{
if(l==r) return (Status){nums[l],nums[l],nums[l],nums[l]};
int m = (l+r)>>1;
Status lpus = get(nums,l,m);
Status rpus = get(nums,m+1,r);
int lSum = max(lpus.lSum, lpus.iSum + rpus.lSum);
int rSum = max(rpus.rSum, rpus.iSum + lpus.rSum);
int iSum = lpus.iSum + rpus.iSum;
int mSum = max(lpus.rSum+ rpus.lSum,max(lpus.mSum, rpus.mSum));
return (Status){lSum,rSum,mSum,iSum};
}
int maxSubArray(vector<int>& nums) {
if(!nums.size()) return 0;
return get(nums, 0 , nums.size()-1).mSum;
}
然后我们分析一下时间和空间复杂度。
时间复杂度:,我们把递归过程看成二叉树的先序遍历,那么这颗二叉树时间复杂度:假设我们把递归的过程看作是一颗二叉树的先序遍历,那么这颗二叉树的深度的渐进上界为 ,这里的总时间相当于遍历这颗二叉树的所有节点,故总时间的渐进上界是 ,故渐进时间复杂度为 。 空间复杂度:递归会使用 O(\log n)O(logn) 的栈空间,故渐进空间复杂度为 。
315. 计算右侧小于当前元素的个数
给定一个整数数组 nums,按要求返回一个新数组 counts。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。
示例:
输入:[5,2,6,1]
输出:[2,1,1,0]
解释:
5 的右侧有 2 个更小的元素 (2 和 1)
2 的右侧仅有 1 个更小的元素 (1)
6 的右侧有 1 个更小的元素 (1)
1 的右侧有 0 个更小的元素
#include <iostream>
#include <vector>
#include <algorithm>
#include <unordered_map>
using namespace std;
struct SegmentNode
{
int start;
int end;
int sum;
SegmentNode *left;
SegmentNode *right;
SegmentNode():start(0),end(0),sum(0){}
};
class Solution{
public:
//---------------------------Segment tree solution----------------------------
inline void build(SegmentNode *self, int l, int r)
{
if(l>r) return;
self->start = l;self->end = r;
if(l==r)
{
// self->sum = l;
return;
}
int mid = (l+r)>>1;
self->left = new SegmentNode();
build(self->left,l,mid);
self->right = new SegmentNode();
build(self->right,mid+1,r);
// self->sum = self->left->sum + self->right->sum;
}
inline void add(SegmentNode *self, int pos, int k)
{
if(pos<self->start||pos>self->end) return;
if(self->start == self->end)
{
self->sum += k;
return;
}
if(self->right->start>pos) add(self->left,pos,k);
else add(self->right,pos,k);
self->sum = self->left->sum + self->right->sum;
}
inline int search(SegmentNode *self, int i,int j)
{
if(i>j) return 0;
if(i<=self->start && self->end<=j)
{
return self->sum;
}
int s = 0;
if(self->left->end>=i) s+=search(self->left,i,j);
if(self->right->start<=j) s+=search(self->right,i,j);
return s;
}
vector<int> countSmaller_SegmentTree(vector<int>&nums)
{
if(!nums.size()) return nums;
SegmentNode *root = new SegmentNode();
//find the min and max val in nums
int min_val = INT_MAX, max_val = INT_MIN;
for(auto &c:nums){min_val=min(min_val,c);max_val = max(max_val,c);}
build(root,min_val,max_val);
vector<int> res(nums.size());
// for(auto &c:nums)
// add(root,c,1);//All sub interval adds 1
for(int i = nums.size()-1; i>=0;i--)
{
add(root,nums[i],1);
res[i] = search(root,min_val,nums[i]-1);
}
return res;
}
//------------------------------Fenwick Tree Solution----------------------------------
//Due to the uncertainty of scale of data, we discretize the array
int n;
vector<int> tr;
int low_bit(int x)
{//pow(2,x)
return (x&(-x));
}
int sum(int k)
{
int res = 0;
for(int j = k; j>0; j-=low_bit(j)) res+=tr[j];
return res;
}
void add(int k, int w)
{// add k to node w
for(int j = k; j< tr.size();j+=low_bit(j)) tr[j]+=w;
}
vector<int> countSmaller_Fenwick(vector<int>&nums)
{
if(!nums.size()) return {};
int n = nums.size();
vector<int> res(n);
//First, we discretize the vector and delete the repeated nums
vector<int> tmp = nums;
sort(tmp.begin(),tmp.end());
auto c = unique(tmp.begin(),tmp.end());
tmp.erase(c,tmp.end());
int new_len = c - tmp.begin();
// we define a unordered-map to count the number of tmp
unordered_map<int,int> ump;
tr = vector<int>(new_len + 1);//redefine the tr to (new_len+1) default value
int count = 1;
for(int i = 0;i<new_len;i++)
ump[tmp[i]] = count++;//redefine the discretized values into serialized values using hashmap
//we build the Fenwick tree and do summation and addition
for(int k = nums.size()-1;k>=0;k--)
{
count = ump[nums[k]];// count of number
res[k] = sum(count-1);
add(count,1);
}
return res;
}
};
感谢!有任何问题请在评论区提出,笔者看到会及时回答!